
Qualität bedeutet ein Produkt, das ich kenne und dessen Schwächen ich kenne, so herzustellen, dass ich es selbst gern besitzen würde. – Jürgen Krech
Vor kurzen landete ich in einem Projekt, dass in die Wartung übernommen wurde. Bei einem ersten Gespräch mit dem Kunden kam es zur Aussage: «Die Performance ist zufriedenstellend, aber nicht gut.» Da auch die laufenden Kosten reduziert werden sollen, fiel der Entscheid die bestehende Oracle Datenbank durch SQL Server Standard zu ersetzen. Für das überführen des Schemas und der Daten nutzen wir den SQL Server Migration Assistent (SSMA). Bei der Datenmenge hatte SSMA mit dieser Datenbank seinen Meister gefunden. Nach einem kurzen Austausch mit Microsoft war die Migration mit ein paar Extra-Kniffen im SSMA erfolgreich.
Vorgängig haben wir Characterization-Tests erzeugt, damit wir die Funktionsweise der bestehenden Software weiterhin gewährleisten konnten. Bevor wir mit der Migration begannen, bediente unser Kunde die Software und wir zeichneten im Hintergrund die Anfrage- und Rückgabewerte auf. Wenn dich das Thema Characterization Tests interessiert, dann kann ich dir das Buch «Working Effectively with Legacy Code» empfehlen.
Als wir die SQL – Server Migration abgeschlossen hatten, bediente ein Tester des Kunden erneut die Applikation. Diesmal lief jedoch der SQL Server Profiler, damit wir die langsamen Abfragen eingrenzen konnten. Du fragst dich jetzt, warum es dafür einen Tester des Kunden braucht? Nun ja, wir hatten die Anwendung von einem anderen Lieferanten übernommen und wir wollten vermeiden, dass wir Dinge optimieren, welche am Ende gar nicht mehr benötigt werden. Des Weiteren bevorzuge ich in der Projektzusammenarbeit das Three-Amigos Pattern.
Im SQL Server Profiler fielen uns dabei auch Abfragen auf, welche bis zu 30 Sekunden benötigten. Diese schauten wir genauer an und ich fand auch Optimierungspotenzial. Eine Abfrage wurde in C# mit ExecuteScalar ausgeführt. Als ich die SQL-Abfrage dazu im SQL-Server Management Studio (SSMS) ausführte, musste ich erst mal überlegen. Diese lieferte über 8 Millionen Datensätze zurück.
Der Ausführungsplan im SQL-Server sah wie folgt aus:
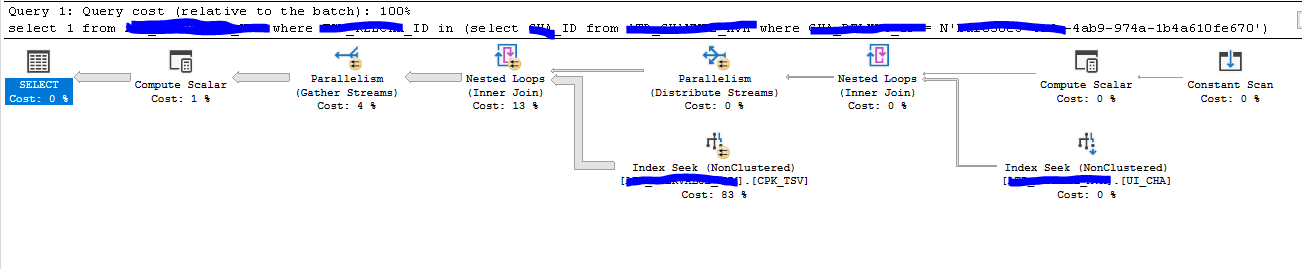
Trotz Index-Seek Operationen war die Ausführung der Abfrage sehr kostenintensiv. Die Statistiken dazu sagten folgendes:
- Table ‘XXXX’. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- Table ‘XXXX’. Scan count 81, logical reads 141985, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- Table ‘Worktable’. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Die Methode ExecuteScalar der Klasse SqlCommand interessiert jedoch nur die erste Spalte der ersten Zeile, alles andere wird verworfen. Die Methode in C# gab auch nur ein true oder false zurück.
public bool HasXXX(Guid Id)
{
using (var connection = this.DatabaseConnection)
{
connection.Open();
using (var command = CreateCommand(@"SQL",connection))
{
var hasValues = command.ExecuteScalar();
return hasValues != null;
}
}
}
So konnten wir auch gleich unsere Characterization Tests ausprobieren. Diese Abfrage musste schneller werden, die Funktionalität dabei unverändert bleiben.
Die Ausgangsabfrage, welche mehr als 8 Millionen Datensätze zurücklieferte, sah in etwa so aus.
select 1 from TABELLE where REL_ID in ( select ID from TABELLE2 where RELMLO_ID = N'baf850e3-416a-4ab9-974a-1b4a610fe670' )
Da im Quellcode nur die erste Spalte der ersten Zeile ausgewertet wird, überarbeitete ich die Abfrage in folgende Version:
SELECT TOP 1
1
FROM TABELLE tser
INNER JOIN TABELLE2 cha ON tser.REL_ID = cha.ID
WHERE RELMLO_ID = N'baf850e3-416a-4ab9-974a-1b4a610fe670'
Der Ausführungsplan zeigte folgendes Resultat:
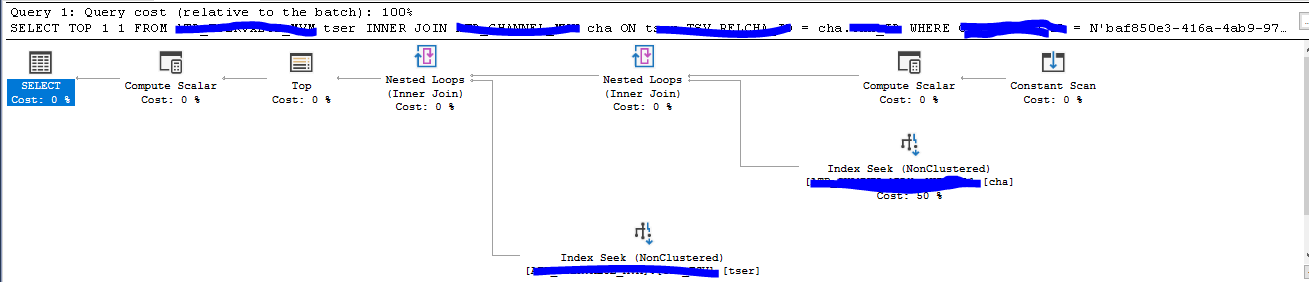
Die Pfeile sind im Vergleich zum ersten Ausführungsplan wesentlich dünner, ein Anzeichen das weniger Ressourcen benötigt werden. Die Statistiken zeigen nun auch ein anderes Bild:
- Table ‘XXXX’. Scan count 1, logical reads 11, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
- Table ‘XXXX’. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Die Worktable wird nicht mehr benötigt und der Scan Count und die logical reads konnten mit der optimierten Abfrage massiv reduziert werden.
Wenn die beiden Abfragen in Relation gestellt werden, dann zeigt sich folgendes:
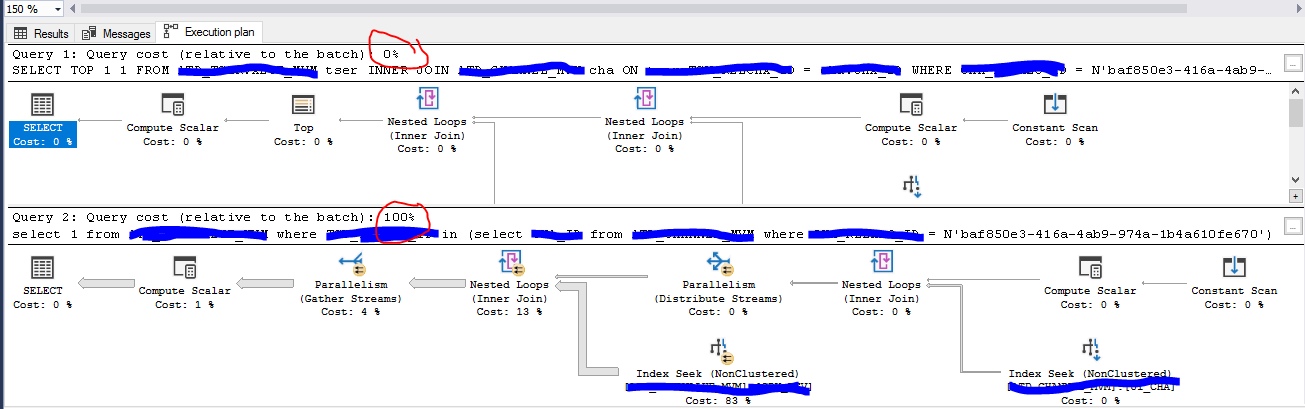
Die überarbeitete Abfrage ist so effizient, dass die Kosten in Relation zum Batch bei 0% liegen. Die Ausführungsdauer beträgt nun 10 ms. Die Ausführungsdauer der alten Abfrage 22’049 ms. Im Vergleich ist die überarbeitete Abfrage ca. 2’200 mal schneller. Eine ideale Kennzahl für ein PAR-Statement.